Принципы Генерации Изображений
Определение
Image Processing = Picture Processing = преобразование изображение с высокой Редундантностью в другое (улучшенное) высоко редундантное изображение и его Компрессия (сжатие по размеру хранилища)
Примеры: сканнер, цифровой ксерокс, цифровое фото, цифровое ТВ, а также цифровой рентген, компьютерная томография и т.д.
Важно: не путайте понятие Image Processing с понятием Computer Vision! И то и другое обрабатывают изображение, но Computer Vision в результате проведения анализа, выдает не новые изображения, а математические значения, измеренных величин.
Важно: Не путайте Computer Vision с Компрессией! И то и другое уничтожают Редундантность, однако, Компрессия лишь консервирует изображение с возможностью последующего восстановления, в то время, как Computer Vision уничтожает изображение полностью.
Растровая Матрица
Растровая Матрица (см лекцию: Растровая Графика ) - это Цифровое Изображение, создающееся различными устройствами - такими как Камеры и Сканнеры через процессы Дискретизации и Квантования.
Иногда Растровые Матрицы создаются в ручную или генерируются Машиной.
Важные определения:
Дискретизация: Отображение реального мира на сетке чувствительных сенсоров.
Квантование: Отображение аналоговой Оси Светлоты на ограниченном множестве целых чисел = АЦ-преобразование.
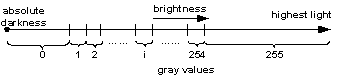
Оцифровка: = идущие друг за другом процессы 1) Дискретизации и 2) Квантования.
Бинаризация: = Квантование на две ступени (часто: 0-1 или 0-255) с учетом установленного порога Светлоты.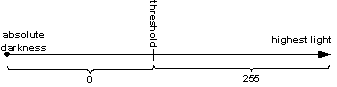
Принципы Дискретизации
Чтобы создать растровую матрицу - считывающее устройство должно выдать следующие данные:
1. количество Колонок и Строк x и y
2. для каждого места x,y реального Мира получить (измерить) следующие коэффициенты:
Энергия I света, падающего из места x,y реального Мира, деленного на энергию I0 света, падающего на место x,y реального мира : quotient(x,y) = I / I0.
Этот коэффициент должен быть пересчитан в значение градации серого или цвета:
grayvalue(x,y) = function( I / I0);
Альтернативы создание Растровых Матриц M(x,y):
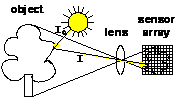 | a) Считывание с ненаправленным светом и множеством сенсоров (Фото): | |
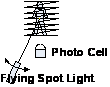 | b) Считывание с направленным светом и одним сенсором (Сканнер): | |
 | c) Считывание непроницаемых объектов = Дискретизация Отражения: | |
d) Считывание прозрачных объектов = Дискретизация Трансмиссии: |
Примеры:
Фото-считывание непрозрачных объектов: Фото, Видео.
Сканирование непрозрачных объектов: Сканнер, Копировальная машина, Радар
Фото-считывание прозрачных объектов: Диапозитив, Diapositiv, LCD-Проекторы, Рентген, Микроскопия клеток и тканей.
Сканирование прозрачных объектов: Компьютерная Томография, УЗИ, Гамма-Камера.
Смешанные формы: Профессиональные Сканнеры и Копировальные машины являются смесью из Фото-считывания и сканирования. Они содержат один или несколько отдельных сенсорных массивов, как правило, с 4096 сенсорами = Фото-принцип, которые передвигаются параллельно с помощью линейных моторов = Сканнер-принцип.
Лучшее качество изображения выдает комбинация из сканерного и трансмиссионного считывания: много времени, никакого рассеивания, никакого затенения и высокие Коэффициенты позволяют получить более высокое разрешение и четкость изображения.
Компрессия
Картинки содержат огромную Редундантность и соответственно требуют большого места для хранения и более широкий канал передачи данных. При технических ограничениях встает вопрос об уничтожении Редундантности - уменьшении Длины Кода = Компрессии.
Уменьшение Кода определяется следующим коэффициентом:
Codelength after
Kompression = ------------------- * 100%
Codelength before
При этом в числителе и знаменателе стоят значения количества элементов кода одного типа (обычно Биты).
Различаются следующие виды Компрессии:
a) компрессия без потерь, что значит - из компрессированных данных можно полностью восстановить предыдущее изображение.
b) компрессия с потерями - восстановленное изображение, в общем случае, хуже оригинала.
Минусы компрессии:
1) Перед записью Картинка должна быть обработана программой Компрессии.
2) Перед отображением Картинка должна быть обработана программой Декомпрессии.
3) Программы Компрессии и Декомпрессии должны зеркально соответствовать друг другу.
4) Программы Компрессии и Декомпрессии требуют загрузки железа и временной памяти.
5) Компрессия предсказуема только статистически, но может сильно отличаться индивидуально для каждой Картинки.
6) При Компрессии с потерями - предсказать потери можно только статистически.
Наиболее старая и часто используемый метод:
Компрессия Изображений без потерь = Run Length Code = RLC = Run Lenght Encoding = RLE
используется для передачи Факсов.
Суть метода в передаче пакетов нулей и единиц.
Первое, третье, пятое число содержит количество нулей в строке, а второе, четвертое, шестое число содержит количество единиц в строке. Пустая строка кодируется одним целым числом = количество точек в строке.
Строки, начинающиеся с единиц на первой позиции получают один ноль.
Часто строка заканчивается восклицательным знаком - разделителем строк для распознавания ошибок (см. ниже).
Это хороший метод Компрессии для текстов (факсов), где средняя количество черных точек всего 2% и поэтому количество нулей непомерно высоко.
Пример: 4-- строчное бинарное изображение B
0011001000 22213
B = 0101010000 -> RLC = 1111114
1010101001 0111111121
0111110000 154
Summ = 40 Bit Summ = 25 Integer
Этот пример сжимает 40 бит в 25 целых чисел. Обычно используется тип UInt16 (= 16 Bit без знака). Таким образом Компрессия равна 25*16Bit * 100% / 40Bit = 1000 %.
Т.е. запакованная Картинка с 10 раз больше незапакованной.
Компрессия выше 100% конечно никому не нужна.
Такое бывает, если:
1) Картинки очень маленькие;
2) Картинки имеют часто меняющееся содержание (рябь);
3) Картинки, которые уже запакованы.
Реальные бинарные картинки с длиной строки 4096 (как у Факса) имеют как правило Компрессию = 5%, т.е. упакованная Картинка в 20 раз меньше оригинала.
Также с помощью RLC можно сжимать Картинки в цвете или с градациями серого. Для этого - кроме счетчика необходимо указывать значение цвета точек. Тем не менее на картинках с большими одноцветными областями эта Компрессия может быть эффективной.
Пример: AAAAAAABBBB -> A7B4
Если известно количество точек в строке (как у Факса например), то RLC не использует знак переноса строки.
Основание: Приемник складывает поступающие цифры и знает, таким образом, когда строчка закончится. Однако он не может контролировать придерживается ли того же мнения Отправитель, так он не может распознать ошибки передачи - недостающие строчки или неверные длины.
Пример подобной тяжелой ошибки: когда одно единственное число теряется, то Приемник меняет (путает) до конца передачи белый фон с черным изображением.
Включение разделительного знака позволяет сделать следующий обработчик ошибок: если позиция разделителя строк не совпадает с концом строки Приемника, то подается запрос на повторение последней строки. Т.е. редундантные разделители строк повышают надежность передачи данных, хотя и ухудшаю качество Компрессии.
Другие варианты компрессии без потерь:
Метод Фаххмана: более часто встречаемые значения кодируются меньшим количеством бит, реже встречающиеся большим количеством бит.
Алгоритм Лемпеля-Зива-Велча = LZW используется в ZIP, GIF, PDF: Часто используемые последовательности сохраняются только раз, после этого сохраняются только ссылки на эти последовательности.
Компрессия с потерей качества:
JPEG, MPEG на основе Фурье-Трансформации.